
Machine learning (ML) è un termine divenuto ormai di uso corrente. Applicati nella logistica, nell’healthcare, nella finanza, nell’insurance, nel retail, gli algoritmi di machine learning macinano quantità enormi di dati che vengono prodotti quotidianamente dagli utenti e dalle organizzazioni. Se proviamo, più in particolare, a osservare quello che oggi avviene nella cyber security, settore che più ci interessa, bisogna precisare che tali algoritmi vengono utilizzati in massima parte come strumento a supporto della capacità di difesa delle organizzazioni. Esempio lampante le attività di Threat Intelligence che sfruttano il ML al fine di profilare gli attaccanti in maniera dinamica, seguire il passo dell’evoluzione delle minacce, prevedere attacchi, anticipare le mosse di possibili intrusi, fino a identificare i vettori che potrebbero essere utilizzati. 
Tramite i meccanismi di auto-apprendimento, gli algoritmi di machine learning, si rilevano inoltre come un aiuto prezioso per rilevare i pattern delle minacce e sviluppare le strategie offensive e difensive più adeguate in relazione al contesto specifico di riferimento. L’interrogativo, che però, deve maggiormente allarmarci, a fronte di una così sofisticata e accelerata evoluzione, è molto semplice: se gli attaccanti stessi decidessero di utilizzare lo strumento del machine learning per superare le difese dell’azienda cosa succederebbe? Gli attacchi che si avvalgono delle forme più avanzate di Intelligenza Artificiale saranno più temibili? Le tecniche di difesa “intelligente” adottate dalle aziende, sarebbero capaci di riconoscere un attaccante anch’esso “intelligente” e tanto più insidioso perchè in grado di adattare il proprio comportamento in base al contesto dello specifico momento aziendale?
Le capacità predittive messe a rischio dalla “minaccia intelligente”
Difficile dare un risposta definitiva, la cosa più grave risiede, probabilmente nel fatto, per nulla improbabile, che le stesse capacità predittive elaborate dalle aziende, potrebbero risultare vane e inefficaci. Alla luce delle nostre conoscenze una cosa è certa: le piattaforme basate su algoritmi supervisionati sono destinate a non durare molto a lungo. Per comprendere al meglio lo scenario, è bene distinguere due macro-categorie di algoritmi di machine learning, i cosiddetti “supervisionati” e “non supervisionati”. I primi, come si può comprendere dallo stesso nome, utilizzano esempi completi, forniti dall’operatore, per eseguire le attività richieste e vengono utilizzati nel caso di pattern e di comportamenti noti. Per loro natura, questi algoritmi, presentano grandi difficoltà nell’individuare modelli di attacco intelligenti in continuo mutamento. Gli algoritmi non supervisionati invece non ricevo alcuna tipologia di “aiuto”, non partono da uno schema predefinito ma creano in autonomia, attraverso l’analisi costante di dati e grazie alle capacità di autoapprendimento, un modello comportamentale della minaccia. Tali algoritmi di fatto si caratterizzano per una maggiore efficacia, anche se al momento richiedono, purtroppo, un tempo molto lungo nella fase di apprendimento, soprattutto all’inizio della loro implementazione. Questo spiega il motivo per cui sono, in molte situazioni, affiancati da soluzioni di difesa tradizionali.
Esiste già da tempo la cosiddetta IA antagonista, si tratta di tecniche pensate per perturbare i dati, fuorviare l’algoritmo e indurlo a prendere decisioni sbagliate a vantaggio dell’attaccante. Sono diversi gli esperimenti compiuti in questo campo. Dalla modifica ad arte di piccoli pixel in un’immagine può far sì che una immagine sia classificata in modo errato ad attacchi perpetrati via telefono, attraverso l’utilizzo di frammenti di voci registrate per raggirare sistemi di sicurezza vocale o effettuare attacchi di social engineering, sotto le mentite spoglie di persone di fiducia, quando non addirittura autorevoli.
Una palestra per gli “algoritmi”
I nuovi algoritmi dovranno essere pensati per far fronte all’IA antagonista. Ad oggi sono in sperimentazione l’applicazione di dati ibridi, dati perturbati e dati reali per aiutare l’IA a riconoscere e risponde ad eventuali attacchi, tanto che sembra opportuno parlare di una sorta di “palestra” per gli algoritmi. Da alcuni anni sono state sviluppate le Generative Adversarial Networks (GANs), letteralmente reti antagoniste generative, basate su algoritmi di machine learning non supervisionati.
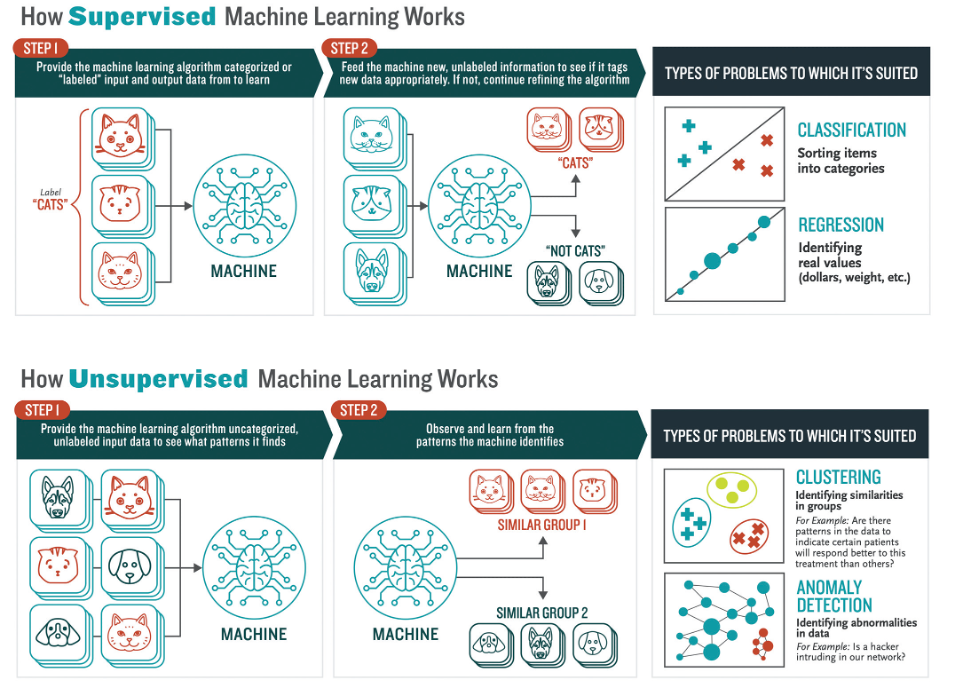 Sistemi “supervisionati” e “non supervisionati”. Infografica ˝ Booz, Allen, Hamilton
Sistemi “supervisionati” e “non supervisionati”. Infografica ˝ Booz, Allen, Hamilton
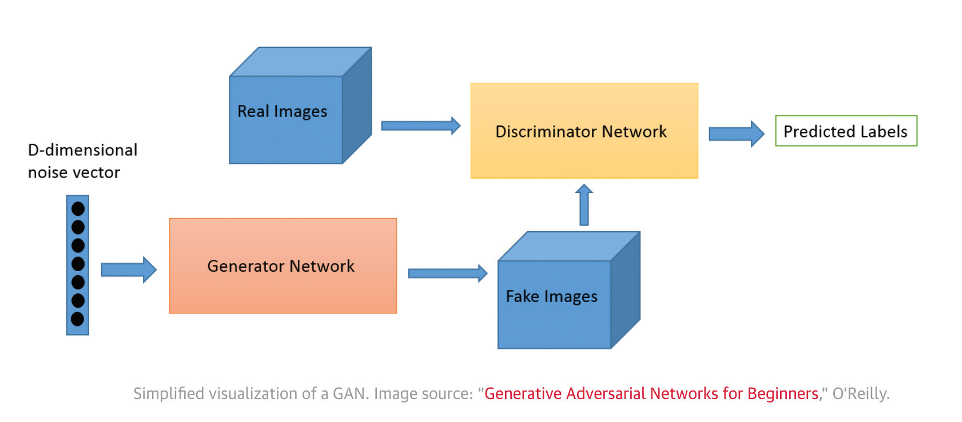
L’architettura è costituita da due reti neurali distinte concorrenti che si sfidano l’una con l’altra. Le GAN hanno ultimamente fatto registrare diverse applicazioni nel campo della cyber security come nell’ambito del riconoscimento facciale, del furto di credenziali, della creazione di malware, finalizzati all’elusione dei sistemi di detection1. Più in generale appare opportuno prendere in esame due approcci nell’utilizzo delle GAN. Il primo in cui la rete GAN viene utilizzata per generare nuovi campioni attendibili che possono quindi servire come dati di addestramento per altri modelli di apprendimento automatico. Il secondo che prevede un vero e proprio “addestramento” della rete GAN, con l’obiettivo di generare dati antagonisti, dal profilo realistico, perciò particolarmente adatti ad ingannare i sistema di sicurezza.2
Altra caratteristica importante che non va tralasciata: gli attacchi basati sull’intelligenza artificiale possono non avere successo al primo tentativo, per poi riuscire con particolare efficacia a centrare il loro obiettivo negli attacchi successivi, questo grazie alle capacità di apprendimento e adattabilità. Sono già in circolazione dei malware “intelligenti” in grado di apprendere automaticamente l’ambiente IT, di identificare i sistemi meno protetti o imitare componenti di sistemi autorizzati e, in caso di rilevamento e blocco, di modificare il proprio comportamento, in modo da avere successo nelle azioni successive.
La frontiera “mobile” delle minacce
Ma i pericoli non finiscono qui. Sono stati sviluppati sistemi intelligenti per la violazione di captcha e password, di Virtual Humint automatizzation o di analisi di vulnerabilità in grado di identificare potenzialmente anche le vulnerabilità zero day da sfruttare. Anche gli attacchi di social engineering e spam intelligente stanno diventando sempre più pericolosi.
 L’intento è quello di inviare una mail che ha come “finto” mittente il Direttore o il capo ufficio, replicandone il modo di scrivere, persino il linguaggio… Un lavoro perfetto, da far sembrare tutto lecito e customizzato per l’ignaro destinatario. Allo stesso modo siamo oggi in grado di simulare una conversazione con un essere umano attraverso gli algoritmi di NLP (Natural Language Processing, elaborazione del linguaggio umano), grazie all’applicazione dello strumento del machine learning. La frontiera dell’innovazione . aperta, per questa ragione bisogna rafforzare i sistema di tutela e di protezione delle reti, che riguardano non solo le attività di business, ma anche la nostra stessa vita, in tutte le manifestazioni del quotidiano.
L’intento è quello di inviare una mail che ha come “finto” mittente il Direttore o il capo ufficio, replicandone il modo di scrivere, persino il linguaggio… Un lavoro perfetto, da far sembrare tutto lecito e customizzato per l’ignaro destinatario. Allo stesso modo siamo oggi in grado di simulare una conversazione con un essere umano attraverso gli algoritmi di NLP (Natural Language Processing, elaborazione del linguaggio umano), grazie all’applicazione dello strumento del machine learning. La frontiera dell’innovazione . aperta, per questa ragione bisogna rafforzare i sistema di tutela e di protezione delle reti, che riguardano non solo le attività di business, ma anche la nostra stessa vita, in tutte le manifestazioni del quotidiano.
Ripensare i nostri sistemi di difesa che dovranno essere sempre più orientati a rispondere a minacce “intelligenti” in grado di attuare le stesse logiche adottate per proteggere i nostri sistemi, diventa in quest’ottica un imperativo categorico, cui nessuno potrà sfuggire.
Autore: Elena Mena Agresti
1 https://www.cs.tufts.edu/comp/116/archive/fall2018/tklimek.pdf




